
In my previous blog posts (1, 2, 3, 4), we delved into how generative AI can enhance research productivity in three key areas: 1) ideation and feedback, 2) writing, and 3) literature survey.
In this installment, I turn my focus to the capabilities of Large Language Models (LLMs) in coding, with a particular emphasis on their proficiency in Python.
To illustrate this, I tasked GPT-4 with conducting an econometric analysis, generating the corresponding code, explaining the code’s functionality, and finally, translating it from Python to R.
As a basis for this exploration, I utilized examples and datasets from Wooldridge’s textbook, “Introductory Econometrics“, and Python codes from Heiss and Brunner’s book, “Using Python for Introductory Econometrics“. The datasets from Wooldridge’s textbook are publicly available for reference.
Enhancing Coding Efficiency with LLMs and Advanced Data Analysis
LLMs, trained on vast online code repositories, excel at a variety of coding tasks including writing, editing, translating, debugging, and even tutoring.
Their ability to generate and weave together code snippets makes them a valuable tool for programmers. This is evidenced by experiments like GitHub Copilot, an AI-powered code completion tool, which has shown a significant increase in programmer productivity. GitHub Copilot provides autocomplete-style suggestions as we code.
The Advanced Data Analysis feature of GPT-4 is a powerful tool that can significantly enhance the efficiency and accuracy of data analysis and code execution tasks, making it a valuable asset for users looking to leverage AI tools for their data analysis needs.
Asking GPT-4 to Conduct Data Analysis
I requested assistance from GPT-4 to develop a script for executing Difference-in-Differences (DiD) estimations. The response provided by GPT-4 included instructions on how to implement a DiD estimation in Python.
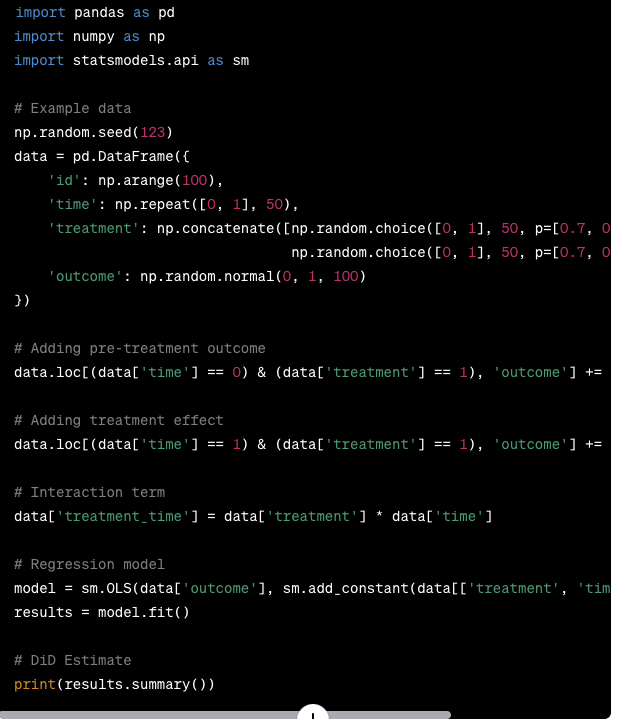
I then asked GPT-4 to conduct difference-in-differences estimations using a real dataset from Example 13.3 in Wooldridge’s book. The following is my instruction to GPT-4.

GPT-4 performed the analysis as instructed and even identified an error in the dataset. Read Content






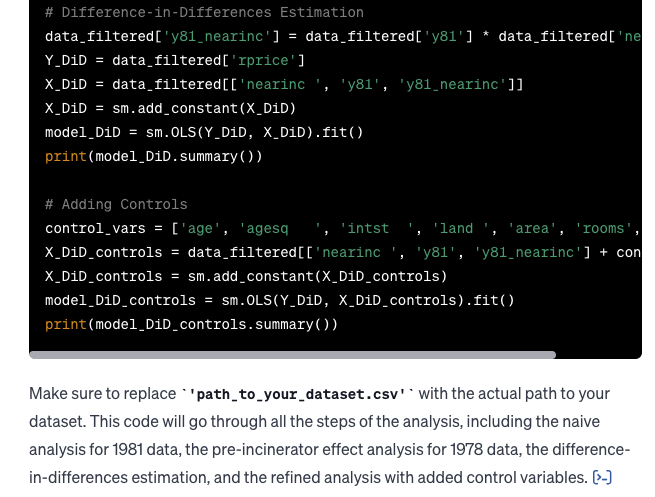
I asked GPT-4 to provide the Python code for the analysis so that I could reproduce it myself. Below is the response from GPT-4. Read Content
I got regression results and Python code without writing any code!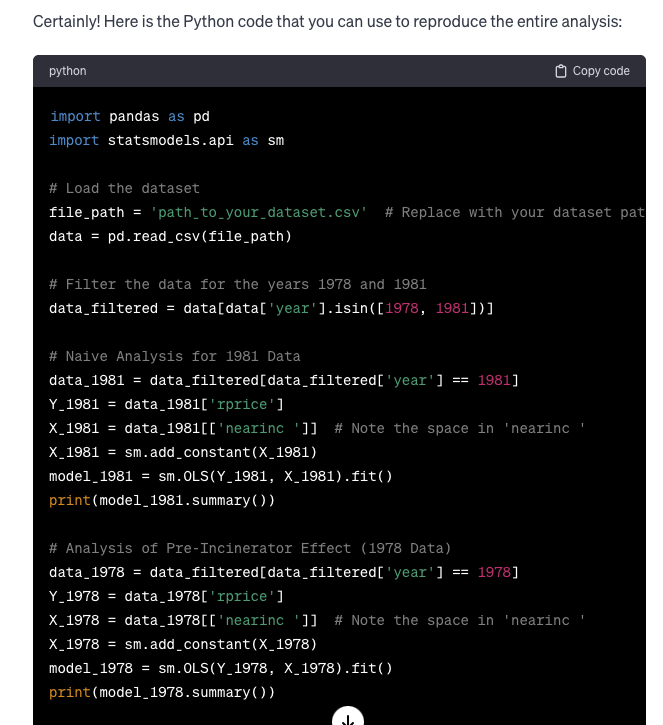
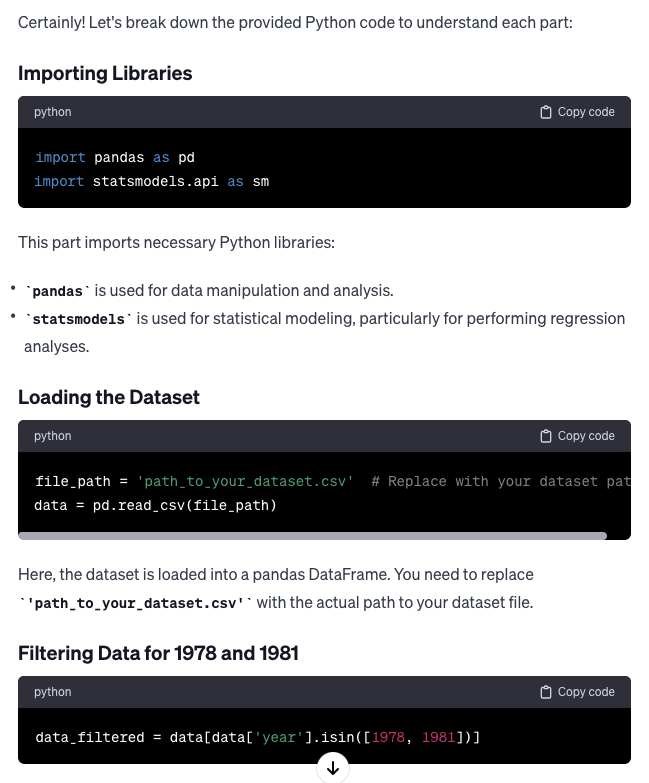
Explaining Code
LLMs also have the capability to explain the functionality of a specific piece of code in plain English. I requested GPT-4 to provide an explanation for the aforementioned code. Read Content
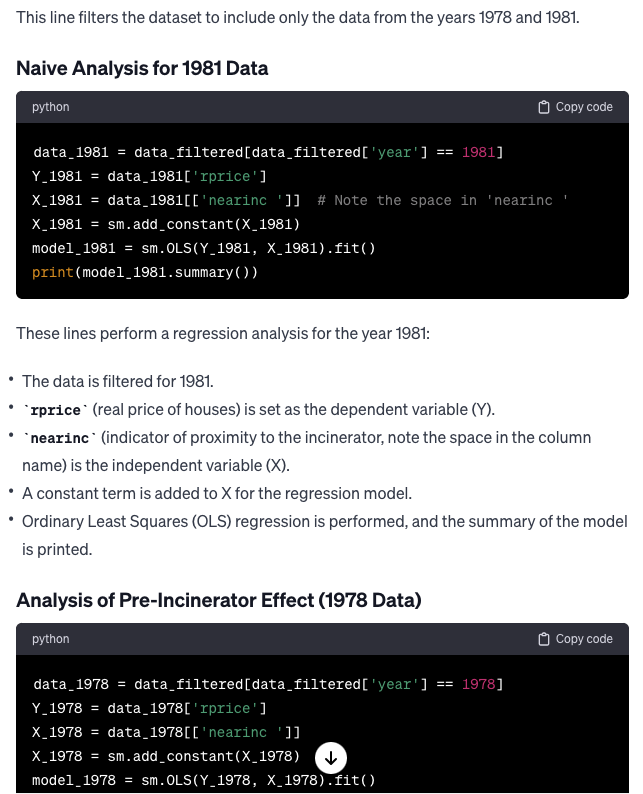
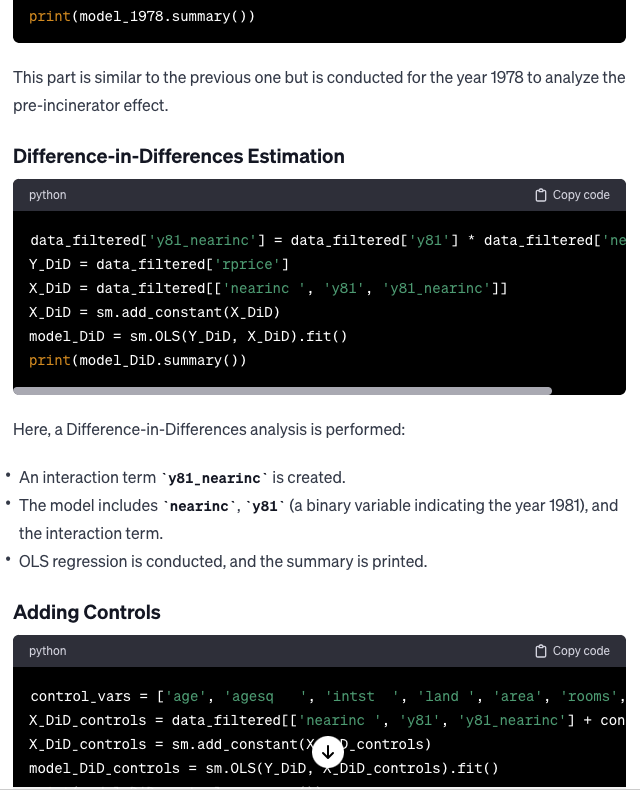

Translating Code from Python to R
LLMs have the ability to translate code from one programming language to another. I requested GPT-4 to convert the aforementioned Python code into R code. Read Content
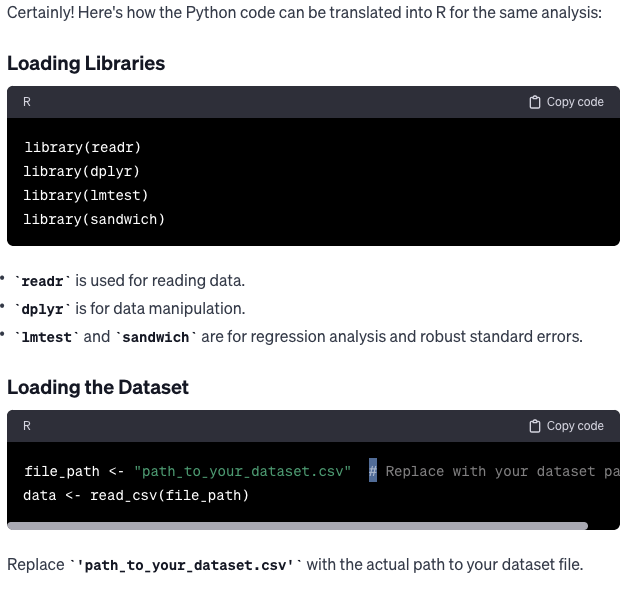
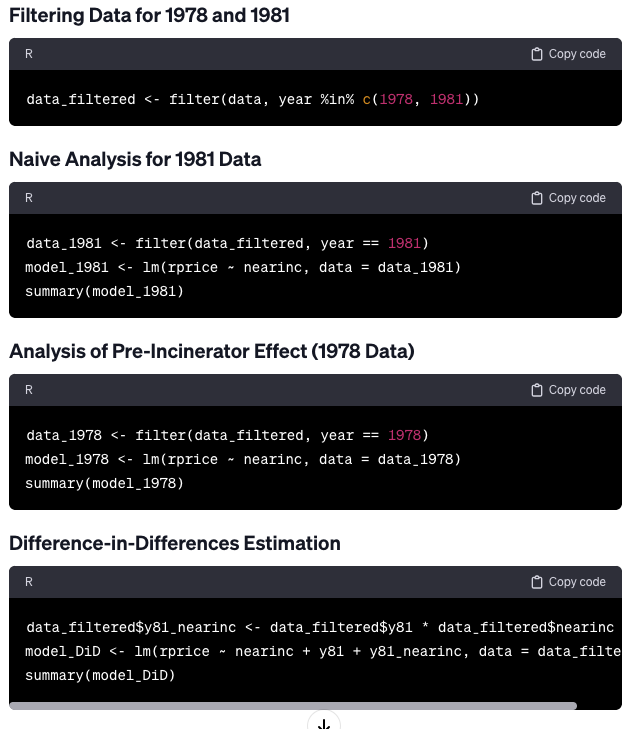
Conclusion: The Future of Coding with LLMs
The capabilities of Large Language Models (LLMs) in coding, as demonstrated in this blog post, are truly remarkable. From enhancing coding efficiency to conducting advanced data analysis, translating code between languages, and even explaining code functionality, LLMs are revolutionizing the way we approach coding and data analysis.
The use of LLMs like GPT-4 in coding tasks has the potential to significantly increase productivity, reduce errors, and make coding more accessible to a wider audience. The ability of these models to understand and generate code can democratize programming, making it possible for anyone to leverage the power of coding in their work, regardless of their background or experience level.
Moreover, the ability of LLMs to conduct advanced data analysis and identify errors in datasets, as demonstrated in the Difference-in-Differences (DiD) estimations example, can be a game-changer in research. It can free up researchers’ time, allowing them to focus more on interpreting results and less on coding and debugging.
In conclusion, the integration of LLMs into our coding practices is not just an enhancement, but a paradigm shift in how we approach coding and data analysis. As we continue to refine and develop these models, we can look forward to a future where coding is more efficient, accessible, and powerful than ever before.
Revolutionizing Research With Generative AI






