
This post focuses on Large Language Models (LLMs) for data extraction from text and Python code generation to analyze unstructured data.
In my previous posts (1, 2, 3, 4, 5), we explored how generative AI boosts research productivity in four key areas: ideation and feedback, writing, literature survey, and Python coding.
Can LLMs Crack the Code of Unstructured Data?
One of the remarkable capabilities of LLMs in data analytics is their ability to extract structured data from unstructured text.
For a comparative analysis, I challenged three leading LLMs—GPT-4, Bing, and Bard—with a specific task.
The task involved taking a paragraph about characters from the beloved Animal Crossing series, each with unique personalities, hobbies, and birthdays, and reformatting it into a structured summary of their names, birthdays, hobbies, and species. To ensure LLMs didn’t retrieve information from the internet, I altered the characters’ names.
Here’s the text they were given:
Mark is a smug cat villager. Mark has the nature hobby. His birthday is October 1. Lucy is a peppy deer villager. Lucy has the education hobby . Her birthday is October 31. Richard is a lazy cat villager. Richard was the first villager created, and his January 1 birthday came as a result of that. Richard has the play hobby. Matt is a smug squirrel villager. Matt has the music hobby and may sing anywhere without the need of a stereo. His birthday is September 29. Max is a lazy bear cub villager . Max has the play hobby. His birthday is April 16 . Reformat as follows: Name & birthday & hobby & species
Unveiling the Process: GPT-4’s Python Code Generation
In response to my request, GPT-4 successfully generated a structured summary that listed each character’s name, birthday, hobby, and species.

Next, I requested GPT-4 to generate the Python code for this analysis, enabling me to independently replicate the results.
The initial code generated by GPT-4 contained errors. Therefore, I informed GPT-4 that I was unable to produce the desired result and asked it to evaluate the code.
GPT-4 attempted to correct the code six times, providing code for each trial and documenting the iterative process towards a solution. After the sixth trial, GPT-4 successfully generated accurate results for Mark, Lucy, Richard, and Matt, but not for Max.
For those interested in my exploration, I am sharing both the code and the results on my GitHub. This serves as a great example of why it’s crucial to verify the code generated by LLMs.
Bard’s Approach
In response to my request, Bard also generated the following summary that listed each character’s name, birthday, species and hobby correctly.

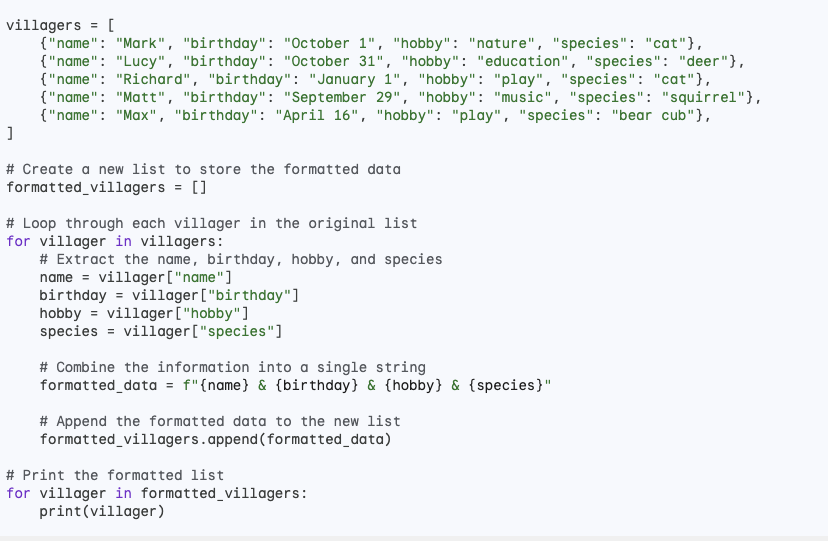
When I asked Bard to provide me with the Python code for the analysis, so I could independently replicate the results, Bard generated the following Python code.
It is evident from the code that Bard simply extracted the information from the summary table it had generated.
Then, I requested Bard to produce Python code for the aforementioned analysis, beginning with the definition of a regular expression pattern to capture the required elements. Below is the Python code Bard generated. Unfortunately, I was unable to run the code.
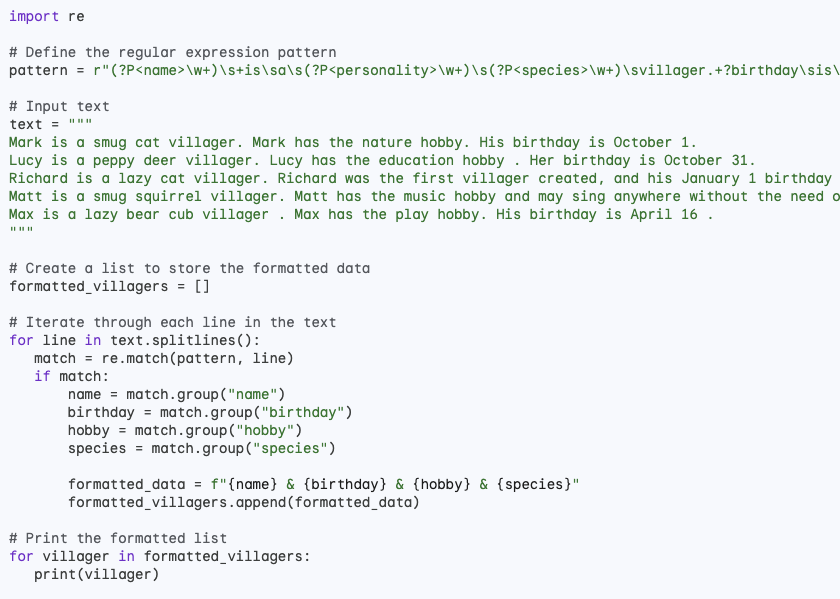
I informed Bard that I was unable to produce the result and requested that Bard debug the code. However, the code generated by Bard after the request for debugging still did not run.
For those interested in my exploration, I am sharing the generated code on my GitHub.
Bing’s Attempt
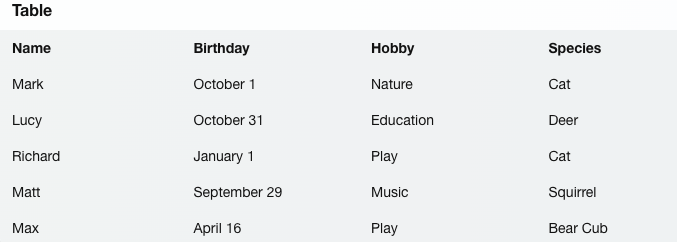
Likewise, Bing generated a correct summary, as shown below, but faced challenges in providing runnable Python code, even after defining a regular expression pattern to capture the required elements.
When I requested Bing to provide me with the Python code for the analysis, enabling me to independently replicate the results, Bing generated the following Python code.
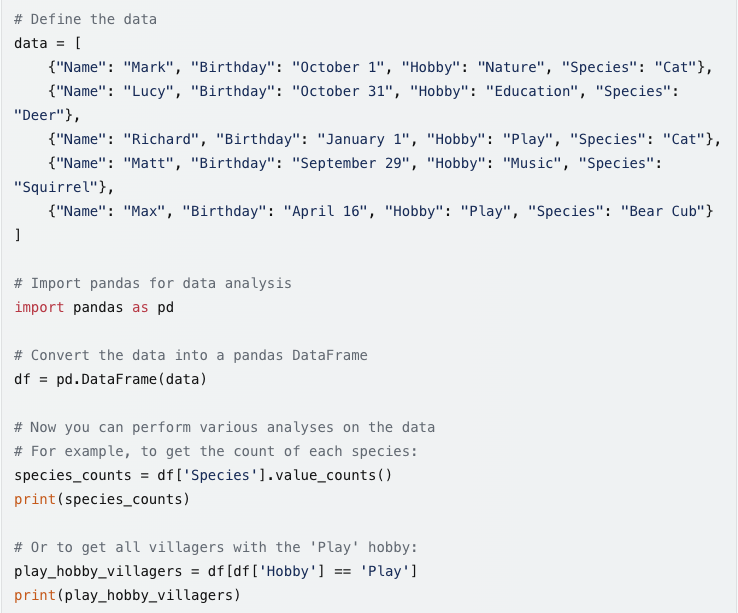
I requested Bing to produce Python code for the aforementioned analysis, starting by defining a regular expression pattern to capture the required elements. However, I was unable to run the code. When I asked Bing to debug the code, the revised code did not work either.
For those interested, I am sharing the code generated by Bing on my GitHub.
Conclusion
The exploration of Generative AI in data extraction underscores both the potential and the challenges in harnessing these powerful tools for research purposes.
The ability of LLMs like GPT-4, Bard, and Bing to transform unstructured data into structured summaries is nothing short of remarkable, demonstrating the advanced state of natural language understanding and processing.
However, the varying degrees of success in generating executable Python code highlight an important aspect of working with AI: the necessity of human oversight and intervention.
Key Takeaways:
- Capability in Data Structuring: LLMs exhibit a strong ability to understand and reformat complex data. This is evident from their performance in extracting relevant information from a narrative text and presenting it in a structured format.
- Challenges in Code Generation: While LLMs can generate Python code, the process is not foolproof. The need for multiple iterations and debugging reflects the current state of AI, where human expertise remains crucial for error correction and optimization.
- Importance of Verification: This exploration serves as a crucial reminder of the need to verify and validate AI-generated code. Relying solely on AI for accurate code generation, especially in research and data analysis, can lead to incomplete or inaccurate outcomes.
- Collaborative Potential: The process exemplifies the collaborative potential between humans and AI. Generative AI can significantly speed up the initial phases of data processing, but human expertise is essential for refinement and finalization.
Looking Ahead:
As AI continues to evolve, we can anticipate improvements in the accuracy and reliability of code generation by LLMs. Future iterations may reduce the need for human intervention, leading to more autonomous data processing systems.
However, the current state of technology reinforces the importance of a symbiotic relationship between human intelligence and artificial intelligence. This balance ensures the accuracy and efficacy of research outcomes.
For researchers and data scientists, understanding the capabilities and limitations of LLMs is vital. It allows for effective utilization of these tools, ensuring that the strengths of AI are harnessed while mitigating its weaknesses through human oversight.
As we continue to integrate AI more deeply into research methodologies, this understanding will be key to unlocking its full potential.
For those who wish to delve deeper into the technical aspects and see the actual code used in these experiments, the code and results are available on my GitHub. This transparency not only allows for peer review and collaboration but also encourages others to conduct similar experiments, furthering our collective understanding of the capabilities of Generative AI in research.
Revolutionizing Research With Generative AI






